Full disclosure, I worked on specs. I’m biased. Specs has evolved quite a bit since I last worked on it years ago, there are some very talented developers who were willing to put in the hard work to improve it. Today it is a better library than it was when I stopped working on it. The developers have done a wonderful job of improving it.
Still, ideas evolve, and there are always different approaches that perform better or worse. Have different ergonomic etc. Legion is one of the ECS that has come onto my attention as it is the planned replacement for specs in the the Amethyst project. It has been a huge project to try and port the code-base over to it, and it is still not complete.
This will probably be the nth description of what an entity component system is if you are in the Rust community. In case you are unfamiliar it’s important that we get you up to speed.
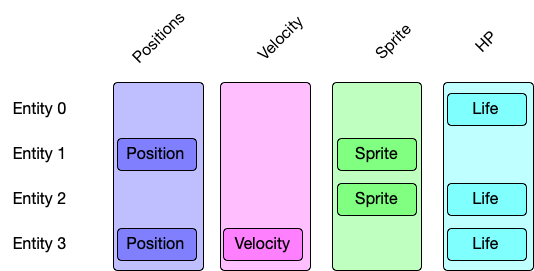
An ECS is short for an Entity-Component-System. I personally like to think about an ECS in terms of a column store database. Each column stores a component in your database, and your entity is your key to associate an object / item in a game engine across the columns. A system works on data at the column level. Components are optional, entities can contain all of them, none of them, or any unique combination of components.
So why do you need one? Well all ECS developers will claim it’s largely about performance, and show you a mountain of numbers to back it up. The more honest answer probably comes down to the difficulty of making ownership work in Rust without some type of framework to manage the transfer of ownership for you. Rust punishes poor architecture, so ECS’ are here to help.
Specs is close to the design of a classic ECS. Each component is stored in a Storage that contains a collection of like elements. The actual storage type can very based on how the user selects.
// Defining a Component
struct Velocity(f32);
impl Component for Velocity {
type Storage = VecStorage<Self>; // <-- You can select the
// type at compile time.
}
// To save some typing for a bring looking trait, there is a
// compiler plugin that does it for you!
#[derive(Component)]
#[storage(VecStorage)]
struct Position(f32);This trait was a clever way that specs can use the compiler type system to keep track of and know statically the type of table. This avoids going via a v-table, or using one generic component storage type for all component types. When the component is requested later, the compiler will know the type and can effectively inline and optimize the iteration though the components.
Writing a system is the next part. A system works over one or more components and does something with them. In this example it modifies the position using the velocity.
// Taken directly from the specs docs
struct SysA;
impl<'a> System<'a> for SysA {
// These are the resources required for execution.
// You can also define a struct and `#[derive(SystemData)]`,
// see the `full` example.
type SystemData = (WriteStorage<'a, Position>, ReadStorage<'a, Velocity>);
fn run(&mut self, (mut pos, vel): Self::SystemData) {
// The `.join()` combines multiple component storages,
// so we get access to all entities which have
// both a position and a velocity.
for (pos, vel) in (&mut pos, &vel).join() {
pos.0 += vel.0;
}
}
}Now to make this all work, specs has some ritual that is involved to setup everything. Specs has a World object which is used to glue everything components/entities together.
// Create a world, and register the components with it
let mut world = World::new();
world.register::<Position>();
world.register::<Velocity>();Internally world creates the storage tables with each register and protects them with some synchronization logic. Components must be registered before they are used, if they are accessed by a system and were not registered, specs will panic and your game won’t be very much fun. Specs internally uses something like an AnyMap, it uses typeid of the Component to relate back to the values you registered here.
At this point, the world has enough context that you can build and register entities if you like. You don’t need to, and they can be created by the systems themselves later if you like.
After a world is created we need to build a Dispatcher which is used as the puppet master of this whole operation. It will sequence the systems and execute them in parallel if they don’t have data dependencies.
Join is the heart of how specs can query multiple components efficiently. It works by using a crate called hibitset. I’m going to skip some of the details of why hibitset is cool, I have talked about it at length before. The interesting bit is that all Storage implementations have a bitset that is associated with the Storage. This is always referenced to know if a value is present or not in the table. Even if the table has its own primary means of knowing (think a HashTable).
This saves space as you don’t require an Option<T> when storing a vector. You can just count on the bitset to test if the value is initialized or not which is more space efficient. This also has the upside that you can combine masks together using boolean operations and then test the combined bitset to know if present in all of the components or not. For example (&position, &velcoity).join() will combine the bit sets before iterating over the content of the data.
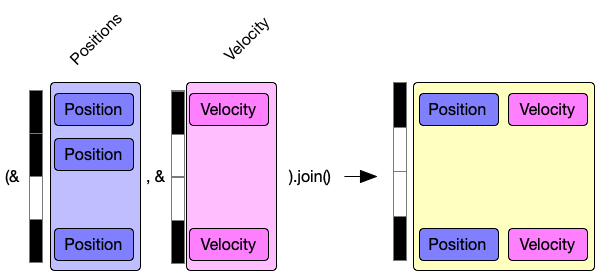
There are some disadvantages of this approach. In tight loops the overhead of searching can easily dominate that actual work you are doing. hibitset is a rather exhaustive data structure and transversing it is not as cheap as iterating though an array, or even a hashmap.
Legion is a new upcoming ECS that uses something called an archetype. An archetype is very different approach to the problems of an ECS. On the surface things look pretty similar.
// Define our entity data types
#[derive(Clone, Copy, Debug, PartialEq)]
struct Position(f32);
#[derive(Clone, Copy, Debug, PartialEq)]
struct Velocity(f32);Important takeaway from this little intro, Legion doesn’t require any the definition of a Storage type like specs did. That’s because Legion doesn’t require the creation of tables for each component type like specs did. All components get’s treated equally even if they are more common than other components.
Like specs you have to create a world object to hold everything. Unlike specs this is created from a Universe.
let universe = Universe::new();
let mut world = universe.create_world();A really nice part of Legion is that the registration step is completely missing from Legion. Legion doesn’t need to know about the types that are being stored by it until they are being stored. Very cool!
This has a benefit because you can use types defined by external libraries. With specs you are required to wrap them like this, which is annoying.
#[derive(Component)]
struct InternalType(ExternalType);
// rust doesn't allow defining trait on types that you didn't define.Systems are created using a builder and a closure.
let update_positions = SystemBuilder::new("update_positions")
.with_query(<(Write<Position>, Read<Velocity>)>::query())
.build(|_, mut world, (res1, res2), query| {
for (mut pos, vel) in query.iter_mut(&mut world) {
pos.0 += vel.0;
}
});The Systems are added to a Schedule which does the same thing as as Specs. Keeps systems all running in parallel without the worry of two systems fighting over the same components.
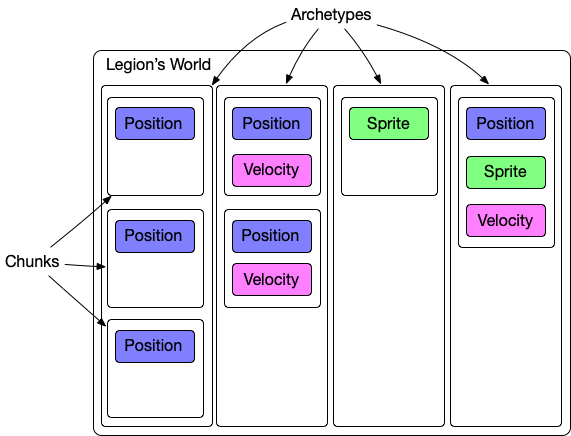
Specs and Legion are not too different to the API user. Legion is arguably a simpler to user in fact. But how they work under the hood is where things get dramatically different. The magic of Legion is Archetypes. An Archetype is a collection of similar entities, similar defined by sharing the same set of components. Meaning an Entity with Position and Velocity is a different archetype than one that just has Position or Velocity.
When an entity is written in Specs, each component gets written to a different storage column. The entity is scattered across the ECS and gets materialized during the read. In Legion, this new entity is written by it’s archetype into a single table that contains entities which identical archetypes.
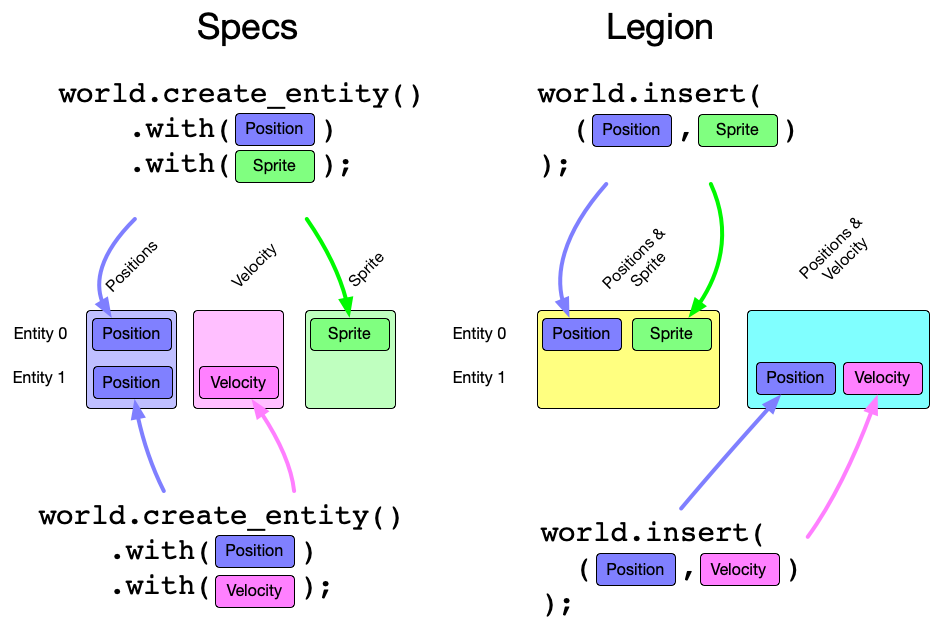
An archetype is a grouping of like entities together. If you have entities with Foo and Bar and one with just Foo and Baz these are held in entirely different tables. Tables are created on demand as new entities are created. If most of your types are similar then they will tend to share a single table. If you have lots of different combinations it creates lots of different tables.
This has some neat advantages! Filtering is done at the archetype level, and not at the entity level. This removes all the expensive and complicated bitmap filtering that was required by Specs to filter entities and moves the process to a pattern of selecting the correct archetypes to transverse. Optimizations are the process of removing work, and that’s a huge amount of work removed. Awesome!
Legion doesn’t interleave the values internally in an archetypes’ storage. So it still has the advantage of being a Structure-of-Arrays rather then an Array-of-Structures. When you are querying an archetype and you don’t need all of the values it contains it doesn’t pollute your cache.
There are some awesome goodies that are also included, like tags which are like components that get shared by a number of elements. But I’m not going to be going in depth over every feature Legion has.
So if you have made it this far and are willing to give Legion a try, you must be asking why would anyone want to use specs over legion?
Legion is really optimized around queries, which is good since they are probably the most common operation an ECS does. This comes at the cost of a few operations, and you have to program around these limitations or else performance will be tanked.
In specs adding or removing a component from an entity is an O(1) operation, it’s just a matter of adding or removing a value from a table. In Legion it’s an O(N) operation, where N is the number of components that entity contains. Legion requires copying the entire entity from one table to another table, adding or removing the entity in the process.
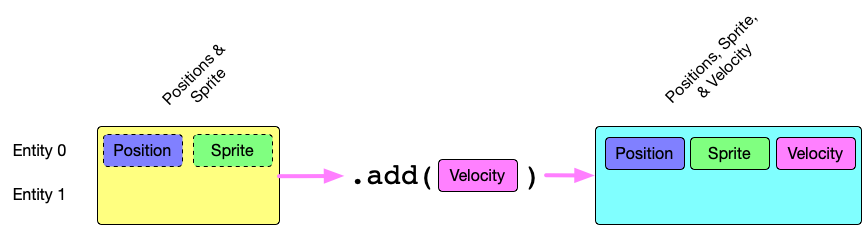
As a side effect of this it’s best to avoid mutations to the “shape” of your entities to avoid shifting of the archetype. Just how bad is it? I did a quick benchmark where an entity with 8 components was created, I then timed how long it took to remove on of the entities. In one micro-benchmark legion took 50 times longer for a single operation.
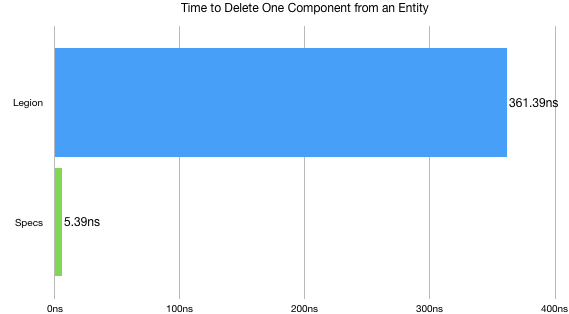
So safe to say, specs is much faster at adding or removing components. The question you should ask is “Does that matter to me?”. Most entities do not change what components they have frame over frame, so perhaps the cost doesn’t matter. That really depends on what type of game you are writing.
Creating entities is O(N) (where N is the number of components the entity is creating, not the number of entities) in both implementations. They both should preform similarly and they do, if all the conditions are setup just right. I microbenchmarked just the creation of entities and ended up trying a few different techniques. The reason this was needed is because of inefficiencies in how each implementation works.
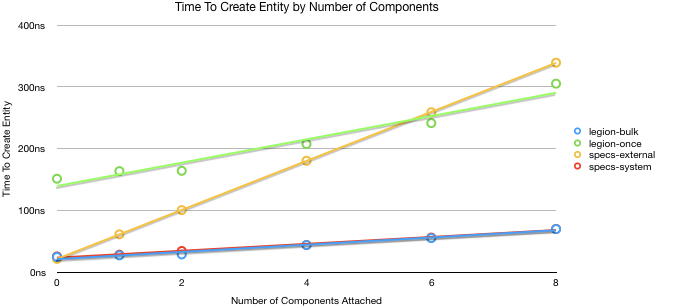
The two benchmarks from Specs, one via the builder pattern, and the other with prelocked components tables. The builder pattern by default will lock and unlock each of the components as the entity is created. While a single lock is not expensive to lock, having to lock multiple components for each entity creation clearly has an adverse effect on performance.
The reason why there are two benchmarks for Legion is that Legion API encourages bulk insertion. Specs has comparably less book keeping required to look up components and modify them. Legion requires searching for the correct archetype that matches it. This process is clearly fast, but noticeable in microbenchmarks. Legions’ API actually has no nice way to create a single entity.
// Legion takes an iterator as input for entity creation
world.insert(
(), // this is a tag, I'll get to it later
(0..iters).map(|_| (A::default(), B::default()))
);
// You can of course use an Option type to mimic an iterator
// of one entity.
world.insert(
(),
Some((A::default(), B::default())).into_iter()
);I like this API. It’s simple, and encourages the user to work the way the ECS work best. It would be maybe a little better if it was something you could chain this with inside of an iterator.
let entites: HashSet<_> = (0..iters)
.map(|_| (A::default(), B::default())
.insert(&mut world) // <-- via extention trait.
.collect();world.insert() does actually return a slice of entities, so the above example would be possible with some more steps. I love the iterator API, and anything that takes advantage of it is awesome in my book.
With some of the downsides discussed, what is the main advantages of Legion’s archetype technique? The answer is iteration performance. The most common operation in an ECS is iteration over one or more components. Think velocity & position, or transform and material. Legion’s archetypes are basically small filtered tables of every entity that are pre-filtered. You just have to select the the correct tables to complete your query.
Iteration performance should be similar to iteration over a vector, since internally it is. There will be some differences, because of the use of structure-of-arrays vs array-of-structures style. In general iterating over an array is kinda like the speed-of-light of iteration performance, assuming you are using all the values you should be bandwidth limited.
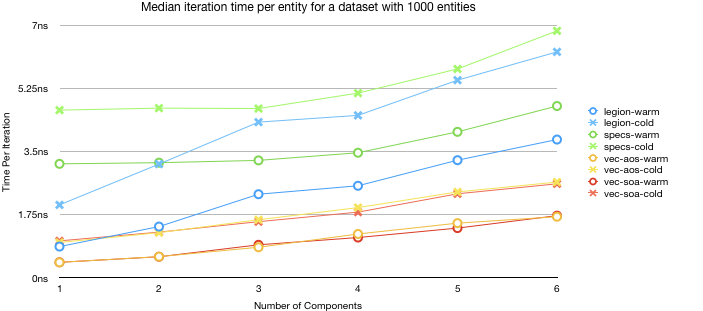
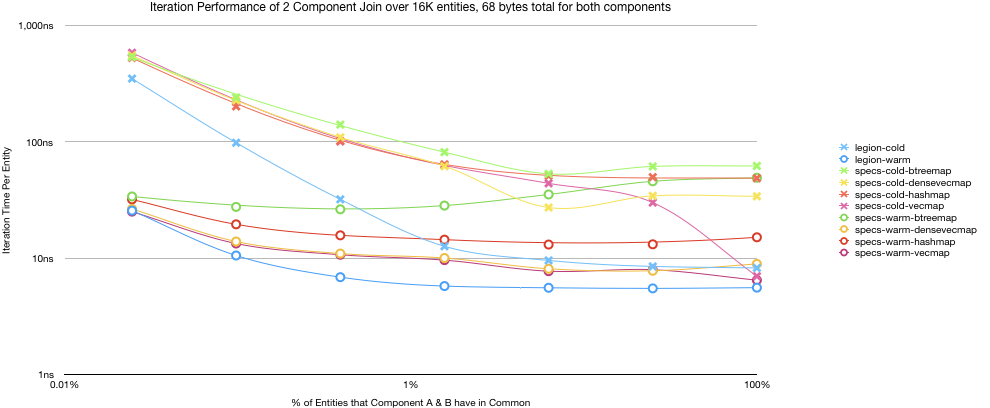
Let’s take a look a quick benchmark of the iteration performance between specs and legion. There are many factors that contribute to iteration performance. The number of entities in the dataset, the size of the components (in bytes), the number of components that we are joining, how warm the cache is. I tried to get enough benchmarks to get a solid conclusion as to what was going on.
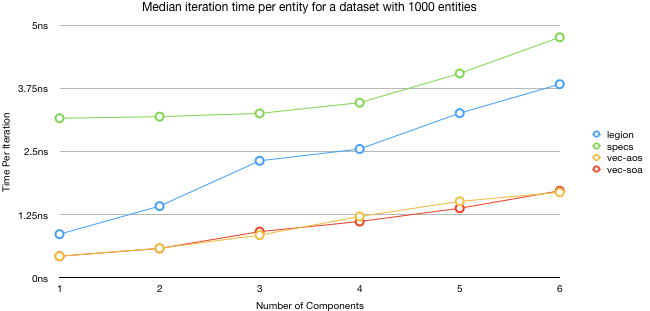
This is the first and probably typical benchmark. The dataset is not huge, but it isn’t trivial in size either. This shows what we would expect, Legion is faster than specs in iteration performance. I added a few other entries vec-aos and vec-soa are array-of-structs and struct-of-array respectively. These just server as a baseline as they are just raw arrays with the correct datatypes in them. They give us an idea of how fast the frameworks could be if there was zero overhead.
Legions’ performance is best with a single component, and gradually decays as more components are added. With a single component legion is more than 3 times faster than specs. It would have been interesting to see this graph go beyond 6 items, but Legion is limited by the size of tuple it built the query trait for, Specs can happily do up to 16 components in its join trait for comparison (there is no architecture reason why there are any limits, but even rust stops supplying traits at more then 12 elements).
specs benchmarks are much flatter by component count. The iterator overhead is the dominate factor for many of the smaller elements and it is only as the data structure gets larger that we can see any other factor. So if specs was to optimize one area to gain performance, the hibitset iterator should be the main target. I suspect there are some gains that can still be squeezed out of this data structure.
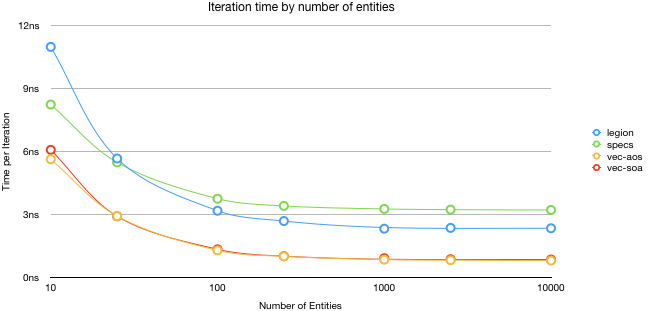
One of the strange things about Legion is that it does have an expensive setup overhead. If you only have a handful of items the time it takes to setup the iterator easily dominate the overhead from iteration over said dataset. This is to the point where in some cases specs overtakes and passes. The crossover point seems to be less then 100 items. We will explore this issue in a bit.
All benchmarks are shown with warm or cold, the difference is that a cold benchmark is done after we thrashed the cache. We then do an entire iteration of the data structure in both cases. We expect warm to be faster, but this measures the effects of cache misses in worst case performance. This was one of the advantages that had been stated as an advantage for Legion over Specs. I wanted to get a better quantification of it.
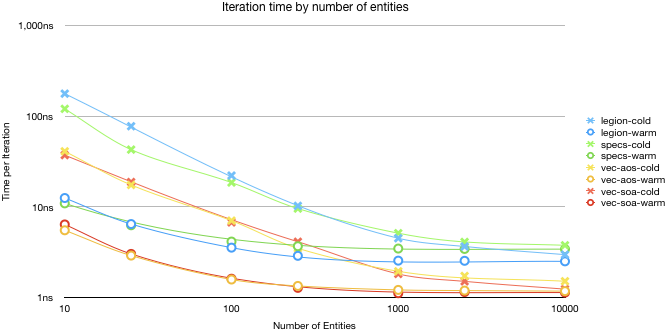
I largely don’t see any major differences, both implementations do terrible compared to raw vectors with a cold cache, but the gap gradually declines as the dataset increases in size and they see the gains of pre-caching. It is interesting that the overhead form a cache miss is not enough to close the gap in the less than three component benchmarks.
Specs and Legion both have areas that can cause poor performance. As they are structured completely differently the areas that will hurt performance are different between the two implementations. The benchmark was designed to show both implementations in their best light for comparative reasons. Now let’s show them in at their worst.
Legion’s performance decays with the number of unique archetypes that exist. The more archetypes the worse the performance will be. This wouldn’t be bad if the number of archetypes was controlled linearly with the component types, but it’s technically logarithmic. I don’t imagine there will be hundreds of archetypes, because the API discourages (via performance) adding or removing components ad-hoc from entities. But it doesn’t if just a few systems start tacking on a components to entities for their own purpose I could imagine situations where the archetypes get scattered.
To demonstrate how bad this can be, I did a quick benchmark where I created entities with an even distribution of unique entity combinations.
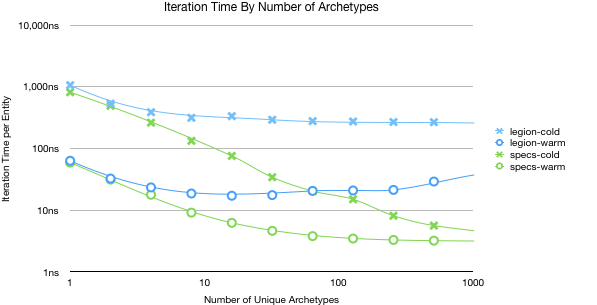
These numbers are pretty terrible but that graph is showing the worst case of having a single entity that matches each archetype. The performance at 1 is a side effect of the number of cache misses that are required before you can iterate over the 1st element. With a warm cache both implementations start with similar overhead but specs quickly dominates being at best ~12 times faster. With a cold cache the gap increases to ~56 times faster in favour of specs.
Once again these are worst case performance. If we look at how the performance changes based on the number of elements in each archetype we can see how the Legions’ performance again does converge and surpasses Specs.
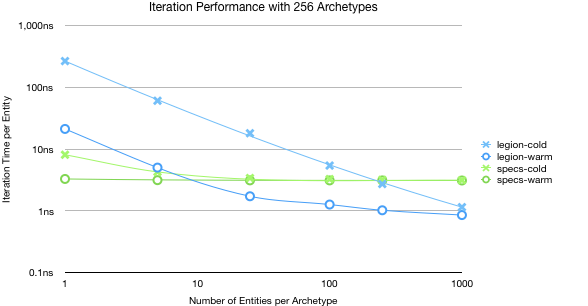
This is the major tradeoff in the design of Legion. It is fast, but it is fastest when types are very homogenous. Specs doesn’t care too much about how many arrangements of components there are unless it effects component density adversely.
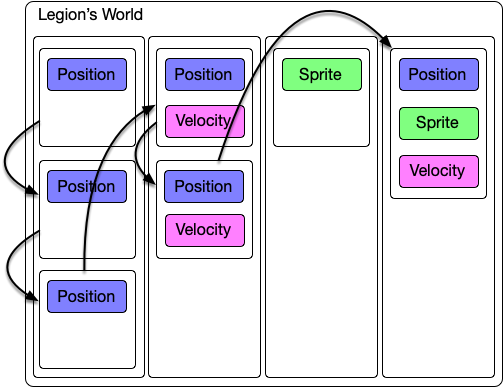
So why does Legion’s performance decay? It's down to how it stores data internally. Legion stores data by their archetypes, these are then internally stored in chunks. Chunks are blocks of entities, they are all uniform sharing the same tags and the same archetypes.
Iteration in Legion is done by filtering the archetypes of the world to find matching ones with the filter (the filter being contains the correct set of archetypes). Once it finds a matching archetype it starts iteration over the chunks, and then iterates internally over that chunk’s data. In the worst case performance we have reduced the amount of data to just a single entity per archetype. This has the effect of reducing the iteration performance to something similar to a linked list.
Specs performance is dependent on what data structures you pick for your component types. A HashMap or DenseVec don’t largely waste much space, but they can suffer from cache locality issues during iteration as the mapping of an entity index to component is not always 1-to-1. Meaning components are pulled into the cached that won’t be read. Specs does have BTreeMaps and Vec based storage, but one is slow, and the other wastes space on unused keys. My experiments were done with Vec because it has the least overhead, and I wanted the most favourable numbers for both.
While specs has a quick way of evaluating which components need to be visited, there is still a caching and pipeline advantages to Legion’s approach that make the performance of specs look pretty bad. Here is a quick benchmark of what component density looks like.
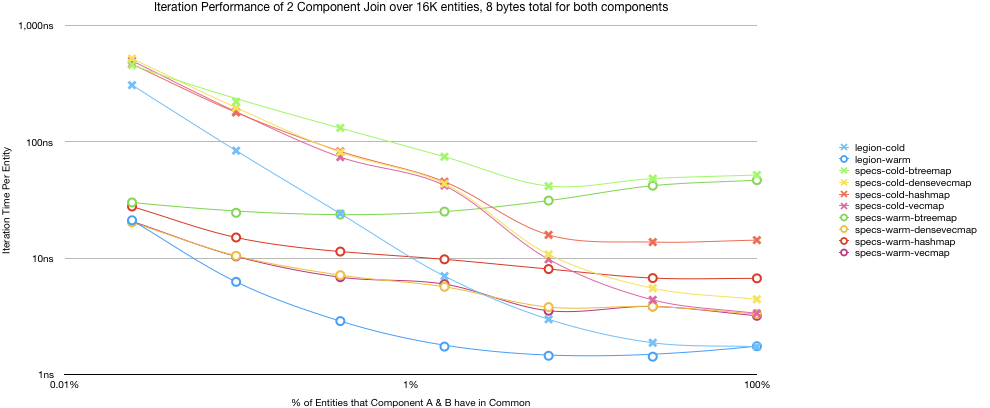
With a warm cache legion is at best 3x faster than specs. With a cold cache the gap is even larger at almost 5x faster. The highest performance delta seems to be around 1% in this case. With higher saturation the performance delta returns to normal. This minor benchmark has some issues, the most of the dataset would fit in the L1 cache of the processor with some spill into L2.
I did another test to check how the performance looks with a larger dataset. Note, I’m not sure this is a realistic size, as iteration over such a dataset might take a millisecond or two.
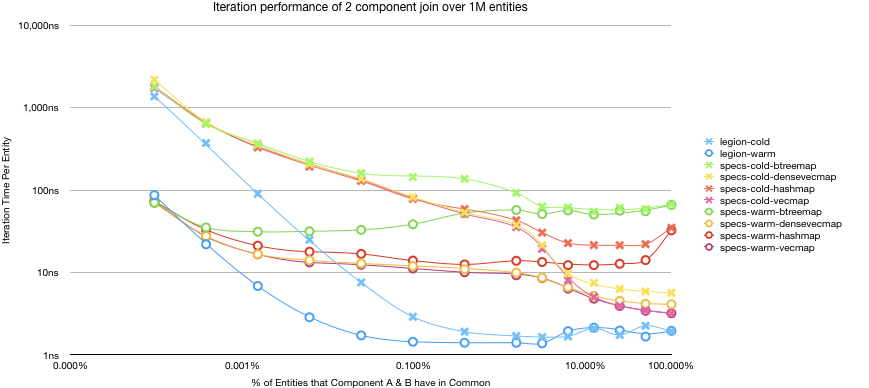
With this larger dataset we can see a larger performance delta. 8x slower with a warm cache and 26x slower with a cold cache. That’s crazy. Looking at this benchmark in isolation would be enough to sell me on Legion.
Component storage in specs doesn’t perform the way my intuitive expectations would have been. For one, the BTreeMap based storage is much slower than I would have expected. Its performance regresses as the dataset gets more populated. Only at very low density is the performance of the BTreeMap actually better then, but once there are more than a few components the performance advantage is lost.
HashMap performance also regresses as the dataset size gets large. This is an effect of the hashing algorithm at work. I wonder if in the future it would make sense to just do a custom hashing algorithm that just uses the entity index to avoid the random access pattern issues that seem to show up as a side effect of a good hashing algorithm.
DenseVec and Vec are the fastest, their performance are very close in these cases. I actually think this benchmark is a poor choice for showing the benefit of DenseVec. The first reason being that DenseVec internally has a lookup buffer that maps the entity index to the real index, this is a u32. The data we are looking up in this case is also a u32, so haven’t saved any memory and we have added indirection for no gains.
Doing a second benchmark with a larger secondary component does seem to help when the cache is cold. The performance between Vec and DenseVec is so close It’s hard to justify DenseVec with the exception of situations where the data structure is huge based on this benchmark alone.
Quick summary of the datatypes in Specs based on these limited benchmarks,
VecStorage if the type is 4 bytes or smaller, or a high percentage of the components will be using this componentDenseVecStorage for any large data types that are not applied to every component.BTreeMapStorage or HashMapStorage only if you are using it for something like need to access them via something like unprotected_storageThis is a little bit of an aside, but I can’t leave a mystery as to why DenseVec and Vec performed so closely. I would have expected DenseVec to have some performance advantages when the saturation of entities was low, but it never showed up in the benchmark above.
Looking at the insert logic for the DenseVec gives us the hint.
pub struct DenseVecStorage<T> {
data: Vec<T>,
entity_id: Vec<Index>,
data_id: Vec<MaybeUninit<Index>>,
unsafe fn insert(&mut self, id: Index, v: T) {
let id = id as usize;
if self.data_id.len() <= id {
let delta = id + 1 - self.data_id.len();
self.data_id.reserve(delta);
self.data_id.set_len(id + 1);
}
self.data_id
.get_unchecked_mut(id)
.as_mut_ptr()
.write(self.data.len() as Index);
self.entity_id.push(id as Index);
self.data.push(v);
}data_id is a lookup table that relates the entity to data’s index and the value is stored in the data vector. So Basically self.data[self.data_id[entity.index]]. The key here is that we are always pushing the data values onto the end of the data array. So the insertion order changes the order of the elements in data.
The logic to attach the entities to random elements in my benchmark was as follows:
entities.shuffle(&mut rand::thread_rng());
for &entity in entities.iter().take(number_with_b_component) {
component_alt.insert(entity, value).unwrap();
}So in effect I was randomizing the order of the entities in the DenseVec and sabotaging its performance. I added a second set of benchmarks to just compare how DenseVec fairs with the same random set of entities, but this time inserted in index order.
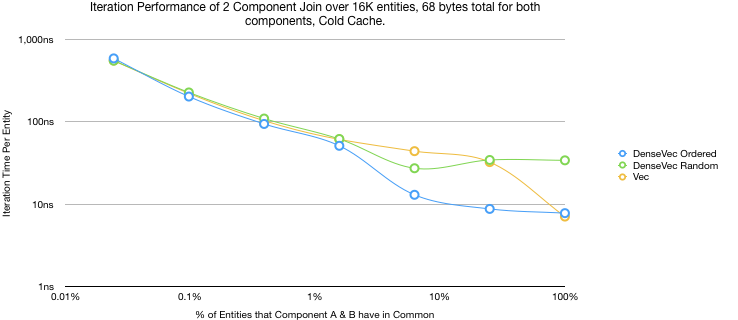
Here we can see the performance advantage I expected. Only being slower than Vec with a 100% saturation. The performance delta is not small either, at peak its almost ~4 times faster. It’s surprising that DenseVecStorage doesn’t have a method to optimize or partial optimize the ordering of entities. It seems like an obvious feature that could run when the system has idle time, otherwise the only way to order it would be to remove all the components and reinsert them.
Both Specs and Legion internally use Rayon for parallelism, which is a good choice. To experiment I wanted to do something simple that was easily parallelizable. One obvious choice is a Mandelbrot set, as it was simple and embarrassingly parallel.

Both specs and legion have methods that allow iteration over entities in parallel. Specs does this via a construct called par_join, which is just like join but turns the iteration into Rayon’s parallel iterator. From that point specs’ job is done and it’s all down too Rayon to figure out how to make it fast. This looks something like this
(&xy, &mut rounds).par_join()
.for_each(|(&Coordinate(x0, y0), rounds)| {
let (mut x, mut y) = (0., 0.);
let mut i = 0;
while i < 100 && x*x + y*y <= 4. {
let x_temp = x*x - y*y + x0;
y = 2.*x*y + y0;
x = x_temp;
i += 1;
}
*rounds = Rounds(i);
});Legion on the other hand provides an interface called par_for_each which is similar but hides the details of the Rayon implementation. This is a little annoying as there are lots of nice patterns that Rayon has supplied that you can chain with your iterator. So we lose helpful methods like filter map count reduce etc. It gets left up the programmer to hopefully do efficiently.
The equivalent Legion code looks like this:
let query = <(Read<Coordinate>, Write<Rounds>)>::query()
query.par_for_each(&mut world, |(coord, mut rounds)| {
let Coordinate(x0, y0) = *coord;
let (mut x, mut y) = (0., 0.);
let mut i = 0;
while i < 100 && x*x + y*y <= 4. {
let x_temp = x*x - y*y + x0;
y = 2.*x*y + y0;
x = x_temp;
i += 1;
}
*rounds = Rounds(i);
});Let’s take a look at how quick this is:
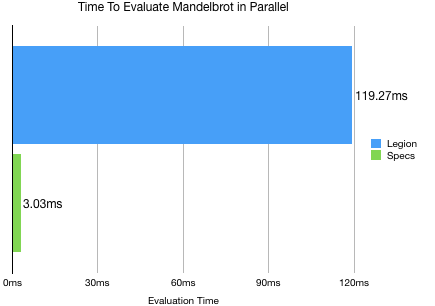
That’s not good. Legion in this benchmark is 40 times slower than Specs. How in that is that possible? This is just iterating over a set of entities, Legion should be faster. The only reason it would be slower is if it wasn’t actually doing it in parallel.
After a night of digging, it looks to me like parallel iterator is broken when working with one archetype. That’s a bug and can be worked around by the developers. There is a way for us to work around to get an idea of how fast legion could be. We can manually shard the data ourselves.
// Some very cursed shard logic
for (i, entity) in entities.into_iter().enumerate() {
let n = i % 256;
if n & 1 != 0 { world.add_component(entity, ShardA); }
if n & 2 != 0 { world.add_component(entity, ShardB); }
if n & 4 != 0 { world.add_component(entity, ShardC); }
if n & 8 != 0 { world.add_component(entity, ShardD); }
if n & 16 != 0 { world.add_component(entity, ShardE); }
if n & 32 != 0 { world.add_component(entity, ShardF); }
if n & 64 != 0 { world.add_component(entity, ShardG); }
if n & 128 != 0 { world.add_component(entity, ShardH); }
}Don’t do that BTW, wait for the authors to fix Legion if you care. That single function over 1.7M data points in the Mandbrot took about 2-3 minutes of prep time before I could get to the few seconds of actual benchmarking.
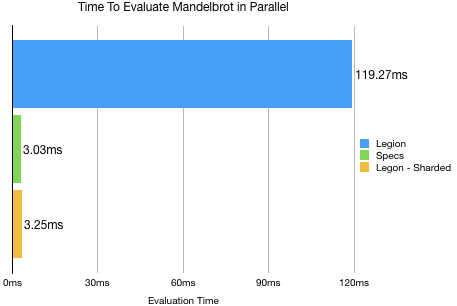
There we are back to a more sane numbers. Legion is a hair behind specs, but given how cursed my sharing logic was, I’ll give it some wiggle room to say it’s multithreading is more then adequate.
Before I get to my conclusions I wanted to mention some of the strange performance weirdness I had seen while evaluating these libraries. I wanted to show both libraries in the best light I could, I’d rather people be discussing their options on data structures then their opinions on my benchmarks.
Legion didn’t compose well as an iterator. I had used iter.take(N) to limit the iteration to the number of elements the benchmarking framework told me to. This worked fine for Specs and Vectors, but with Legion the compiler ended up moving the benchmark to a function call and completely tanking the performance. That would have largely made this article pointless as it would just be questionable benchmarks of Specs being faster in every case. Not interesting to read, and not helpful.
If you stuck with me, wonderful! If you are just skipping to the end, fair enough.
I have a few take aways from this exploration. Legion is fast, at least in its own definition of what fast is. Iteration speeds are really important and it sacrifices quite a bit to actually maximize iteration performance.
Legion is also slow in places. If you are not used to the penalties of adding or removing components it will be a surprise how terrible the performance can be. Several of the benchmarks I created were painful to run because of how slow Legion is in creating the dataset. I imagine this might be frustrating to new comers to Legion, but it would probably be easy to identify such problems early in the development process.
Specs has room for improvement. Its iteration speeds seemed fast when it was introduced, but the competition was largely folk writing an ECS for the sake of getting their games design right not to wow people with performance. I do think specs could be more competitive for performance from where it stand. I don’t think there is a miracle that could make its design faster than Legions for iteration speed.
I do think Legions’ API could use some polish. Specs feels better on the api design front, it’s APIs compose a bit better with other libraries, exposing Rayon or supporting more of libstd’s traits would be helpful. Legions’ is young and will have time to fill in these gaps. Many of these gaps are just oversights in traits that you forgot to implement, and use cases that you didn’t consider.
There are other differences between the two frameworks that I didn’t have time to explore. If they sound interesting I encourage you to try them out.